Digitalizacja zabytkowych1 materiałów bibliotecznych jest w kontekście globalnym dosyć niszowym zagadnieniem, nie ma więc co oczekiwać, że wykorzystywane oprogramowanie będzie kompletnie przyjazne od razu po instalacji. Jednak brak dostępu do rozwiązań, które są wygodnie konfigurowalne i zoptymalizowane nie oznacza automatycznie, że usprawnienie przetwarzania nie jest możliwe i że skazani jesteśmy wyłącznie na to, co dany program domyślnie oferuje jako jedyne i słuszne.
Skoro właściwie zmienić ustawień się nie da, trzeba będzie nadrobić te braki w inny sposób. Koniecznie musimy zapoznać się ze szczegółami tego, jak program materiał przetwarza, z czym ma problem, co robi dobrze oraz jakie, pozornie niezwiązane głównym zadaniem, mechanizmy możemy wykorzystać podczas przetwarzania. Istotna jest też świadomość pierwotnego przeznaczenia używanego programu, gdyż pomaga to zrozumieć dlaczego pewne mechanizmy działają tak, jak działają i dlaczego twórcy pewnych dla nas oczywistych funkcji nie stworzyli w ogóle.
Wpis ten pierwszorzędnie dotyczy FineReadera w procesie digitalizacji, jednak większość sugerowanych rozwiązań zastosować można do dowolnego programu, w którym konfiguracja eksportu jest ograniczona. Przykłady są z wersji 12, aczkolwiek poprzednie większość z tych opcji będą mieć zorganizowanych tak samo lub bardzo podobnie, z jednym drobnym wyjątkiem, który tu jednak nie jest istotny2. Niektóre funkcje mają w różnych wersjach inne nazwy, w miarę możliwości dopiszę też nomenklaturę z wersji 11, innymi wersjami nie dysponuję, więc w takich przypadkach trzeba będzie pokombinować samemu.
Jeżeli chcemy użyć FineReadera do konwertowania historycznych materiałów bibliotecznych, może się nam trochę tych nieoczywistych rzeczy przydać. I o ile dokumentów DjVu lepiej tym programem robić nie próbować, bo niczego sensownego wytworzyć się nam nie uda3, to w przypadku pedeefów sprawa całkiem beznadziejna nie jest. Zaznaczam na wstępie, że bardzo porządnej optymalizacji przy jednoczesnej wysokiej jakości oczekiwać nie sposób, jednak da się tym programem zrobić dokumenty, które przynajmniej nie będą w każdym aspekcie sknocone. Najważniejsza jednak jest zmiana podejścia, ponieważ zrobienie w miarę porządnie przygotowanego dokumentu FineReaderem jest możliwe, wymaga jednak cierpliwości oraz sporego nakładu pracy. Podejście wrzuć—kliknij—wyjmij zupełnie się tutaj nie sprawdzi.
Zbadanie działania programu
Zakładam, że czytający te słowa mniej więcej wie, co to jest FineReader i do czego służy, a także jakieś pobieżne doświadczenie z tym programem ma i potrafi przygotować go do roli w prezentowanym tutaj procesie, która ogranicza się jedynie do rozpoznania tekstu i konwersji do formatu prezentacyjnego. Jeżeli idzie tę ostatnią sprawę, okazuje się, że kilka spraw jest trochę sknoconych — z paru innych da się zmontować jakieś prymitywne ustawienia, żeby mieć wpływ na wynik przetwarzania.
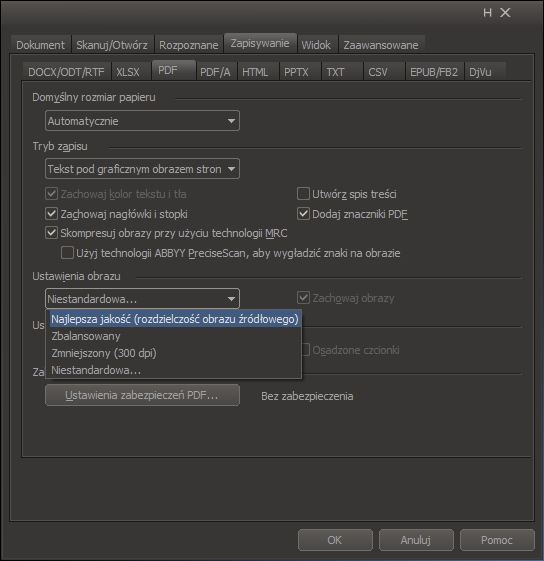
Z całego tego panelu interesują nas trzy rzeczy: Skompresuj obrazy przy użyciu technologii MRC w FR12 lub Użyj mieszanej zawartości rastrowej w FR11 — czyli włącz/wyłącz segmentację, Dodaj znaczniki PDF lub Włącz PDF ze znacznikami — która powinna w naszym kontekście się nazywać Uwzględnij bloki obrazów przy segmentacji, ponieważ to jedyny aspekt tej opcji, który ma znaczenie dla obrazu wynikowego4. Wyłączenie tego powoduje kompletne zignorowanie czegokolwiek, co jest zaznaczone przez blok obrazu i zastosowanie przetwarzania niskiej jakości, tak, jak w przypadku fragmentów niezaznaczonych. Załączenie powoduje zapis obszarów zaznaczonych jako obrazy w wyższej rozdzielczości i z mniejszym stopniem kompresji. O szczegółach tej funkcji pewnie coś jeszcze napiszę, ponieważ często są z tym spore kłopoty. Trzecią istotną opcją są Ustawienia obrazu — lista rozwijana, z której ważne są tylko dwie rzeczy: Najlepsza jakość (rozdzielczość obrazu źródłowego) oraz Niestandardowa… Dwie pozostałe raczej nie mają zastosowania.
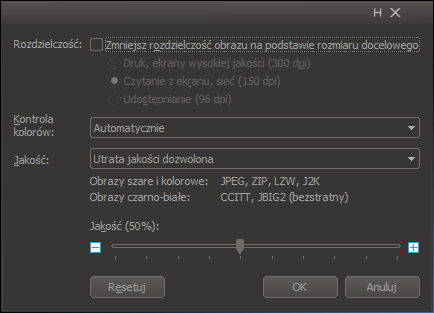
W ustawieniach niestandardowych jest suwak jakości, który na jakość kompresji obrazów ciagłotonalnych nie wpływa, aczkolwiek ma jakąś sztywną wartość niemaksymalną, co pozwala nam użyć tej opcji gdy chcemy bardziej skompresować dokument. Zaznaczamy tam brak zmiany rozdzielczości i automatyczny wybór kontroli kolorów oraz pozwalamy na utratę jakości, pozycja suwaka ma jedynie znaczenie dla bitonalnych obrazów wejściowych, można więc ustawić cokolwiek5.
A teraz bardzo ważna sprawa. Na wynik segmentacji w PDF-ach ma wpływ odpowiednie zaznaczenie bloków. Fakt ten powoduje, że nie da się porządnie zautomatyzować przetwarzania przy jednoczesnej optymalizacji plików wynikowych — ciągła kontrola poprawności zaznaczeń bloków jest więc fundamentalnym warunkiem powodzenia sprawy. Nie można więc na skróty działać, każdą stronę trzeba sprawdzić i bloki poprawić — na co szczególnie uwagę zwracam — wprowadzenie więc PDF-ów i przetwarzanie FineReaderem segmentacji nie przyspieszy ani nie usprawni. Nie wszystko z tego powodu musi być jednak negatywne, być może to dobra okazja do ponownej ewaluacji wskaźników i skupienia się na jakości, skoro i tak trzeba poprawiać i sprawdzać.
Mamy więc pewien ograniczony wpływ na stopień kompresji obrazu wyjściowego oraz sposób segmentacji lub jej całkowite wyłączenie, czyli względnie mało w porównaniu np. z DocumentExpress — z drugiej strony jednak możemy regulować zaznaczenia obszarów, co pozwala na lepszą kontrolę nad zawartością stron i umożliwia ręczne wsparcie segmentacji — w przypadku całkowicie zautomatyzowanego przetwarzania nie było to możliwe w ogóle. Oczywiście poprawia to także jakość rozpoznania tekstu.
Przygotowanie materiału wejściowego
Skoro na etapie konwersji naustawiać wiele się nie da, trzeba to przenieść do poprzedniego etapu, w którym możemy mieć wpływ na kilka rzeczy. Jeżeli chcemy cokolwiek sensownego uzyskać na wyjściu, to zdecydowanie należy odpuścić sobie 300 ppi, ponieważ segmenter FineReadera nie ma kompletnie żadnych optymalizacji dla obrazów o niskiej rozdzielczości, a także dlatego, że nie da się ustawiać dzielników ani jakości kompresji dla poszczególnych warstw. Jeżeli dysponujemy materiałem źródłowym o rozdzielczości 600 ppi, to można go załadować bezpośrednio i bez obaw przetworzyć. Co jednak, gdy mamy tylko 300? Trzeba pliki źródłowe zinterpolować. Docelowo rozdzielczość ok. 500 ppi jest wystarczająca. Więcej niż 600 z 300 robić nie polecam, ponieważ pojawią się dodatkowe kłopoty, które dosyć ciężko się kompensuje, a poza tym 600 wystarcza do większości współczesnych zastosowań. Program dzieli na sztywno przez trzy. Jeżeli podamy na wejściu 600 ppi, to uzyskamy tło o rozdzielczości 200 ppi, które będzie już wystarczalne i w miarę bezpieczne w razie niepowodzenia segmentacji pewnych obszarów6. Warto powiększać obrazy czymś, co dobrze interpoluje. Zdecydowanie odradzam eksportowanie w większej rozdzielczości bezpośrednio ze ScanTailora, gdyż nie radzi sobie wystarczająco dobrze. Świetnie za to radzi sobie z tym ImageMagick, więc na skanach źródłowych, zanim cokolwiek z nimi zrobimy innego, trzeba wykonać:
mogrify -resample 600 -verbose -format jpg -quality 97 *.tif
Tak, można do jpega, o ile się go za bardzo nie ściśnie. A przy okazji nie zastępujemy plików źródłowych, da się więc powtórzyć, jeśli się coś nie powiedzie za pierwszym razem. Stosując odpowiednią rozdzielczość wejściową można ładnie ustalić, co otrzymamy na wyjściu. Poza tym zwiększenie rozmiaru ma bardzo pozytywny wpływ na geometrię znaków, co widać poniżej.

Z prawej: po przetworzeniu z zastosowaniem wcześniejszej interpolacji (600 ppi ze źródła 300 ppi).
Różnica w rozmiarze wynikowego pliku wynosi ok. 210%, otrzymujemy jednak czterokrotne zwiększenie powierzchni i dokładności zarazem. Jak się w praktyce okazuje, przeprowadzenie interpolacji pomaga też na obrazy zaszumione i jpegi z widocznymi artefaktami, w związku z tym w większości przypadków opłaca się to wykonać i tak. Szczegółowo opisałem sprawę tutaj. Gdy już mamy odpowiednio powiększone pliki, możemy je poobracać i przykroić ScanTailorem, poprawić nieco akutancję i ostrość, po czym załadować do FineReadera. Z racji tego, że obrazy mamy już przygotowane, trzeba w FineReaderze wyłączyć przetwarzanie wstępne, ponieważ program pokręci obrazy po swojemu i wprowadzi niespójność rozmiaru stron w dokumencie wynikowym, co brzydkie i nieprofesjonalne jest.
Rozpoznanie i korekta obszarów
FineReader dokona analizy układu strony na każdym ze skanów. Niestety, jak to automat, superskuteczny w tym zadaniu nie jest, a im bardziej złożony lub dziwny dokument, tym mniejsze szanse powodzenia. Z zachowania programu wywnioskować można, że głównym celem przetwarzania są dokumenty biurowe i proste, współczesne książki — z tym FineReader radzi sobie w miarę dobrze i wiele poprawiać nie trzeba. Jeśli jednak mamy do skonwertowania dokument historyczny w nie najlepszym stanie, na dodatek złożony wielokolumnowo i z ilustracjami, sprawa się trochę komplikuje. Problem wynika z odmiennego podejścia do segmentacji obrazu niż w DocumentExpress lub nawet w przypadku robienia DjVu FineReaderem. Przy eksporcie do DjVu całość obrazu zostaje podana segmenterowi do przetworzenia. Przy PDF na wynik mają wpływ zaznaczone bloki. I jeżeli są zaznaczone poprawnie oraz program poradził sobie z ich rozpoznaniem7, to wynik jest dobry. Żeby go uzyskać, należy przejrzeć każdą stronę i wszystkie bloki poprawić.
Zanim zabierzemy się jednak do poprawiania, należy zdecydować jak będziemy segmentować dokument. Przydadzą się nam do tego opcje, które wcześniej opisałem. W porównaniu z klasycznym trójwarstwowym modelem MRC, zastosowanym w DjVu (który tutaj też możemy zastosować), PDF pozwala nam na dodanie jeszcze jednej warstwy — obszarów ilustracji, których rozdzielczość nie będzie redukowana, a stopień kompresji niewielki. Świetna rzecz, jednak trzeba z tym ostrożnie, gdyż łatwo przez niewłaściwe użycie doprowadzić do sporego niepotrzebnego zwiększenia rozmiaru plików wynikowych oraz bardzo widocznych granic między obszarami8, co zmniejsza komfort czytania i generalnie drażni. Podsumowując: decydujemy, czy robimy trzy warstwy, czy cztery. Z doświadczeń moich wyszło, że jeżeli mamy dokumenty, których papier jest ciemny i ma dosyć mocno widoczną fakturę, lepiej robić trójwarstwowo; natomiast bardziej współczesne, które maja gładkie tło, można robić czterowarstwowo. Jeżeli chcemy cztery warstwy, załączamy znaczniki PDF, jeżeli natomiast chcemy trzy — wyłączamy. Oczywiście rodzaj papieru nie jest jedynym kryterium, istotnym przy decyzji o sposobie segmentowania. Przy takim samym materiale wejściowym, przetwarzanie trzywarstwowe da w większości przypadków znacznie mniejsze obrazy niż czterowarstwowe, co może być pożądane. Istnieje jeszcze jedna ważna przewaga trójwarstwowego sposobu konwersji — w ogóle nie musimy przejmować się zaznaczaniem i poprawianiem bloków typu obraz, gdyż zostaną przez program zupełnie pominięte — czyli znacznie mniej roboty przy korekcie. Tryb czterowarstwowy przydaje się szczególnie w przypadku nowych dokumentów, które zawierają bardzo szczegółowe ilustracje — zastosowanie zaznaczeń powoduje eksport tych fragmentów w oryginalnej rozdzielczości. Jeżeli jednak papier nie jest gładki, trzeba się spodziewać tego, że program pozaznacza większość obszaru stron niezadrukowanych jako obrazy, co spowoduje, że niektóre z nich będą mieć przy eksporcie nawet kilka megabajtów i doprowadzi też do pewnej paradoksalnej sytuacji, w której strony niezadrukowane będą lepszej jakości niż zadrukowane, a raczej nie po to optymalizujemy dokumenty :).
Program treść odnalazł i oznaczył — przystąpmy do korekt. Na pewno trzeba pozaznaczać cały tekst, gdyż wszystko, co nie jest zaznaczone podane zostanie segmenterowi w specjalnym trybie, który szuka tylko linii i krawędzi ramek — a to się dla tekstu może skończyć źle9. Poza tym raczej chcemy mieć tekst rozpoznany. Jeżeli stosujemy tryb trzywarstwowy, możemy pozaznaczać jako obrazki te fragmenty skanu, które na pewno mają nie być segmentowane. FineReader ma czasem problem z rozpoznaniem bloku. W obszarze podglądu rozpoznania taki blok będzie widoczny, jednak nie będzie zawierał żadnych znaków (lub będzie brakować fragmentu treści).

Zmiana typu na tabelę też może pomóc.
Aby to naprawić w większości wypadków wystarczy sprawdzić, czy się nie włączyła inwersja tekstu w bloku, a jeśli nie, należy spróbować lekko zmienić rozmiar zaznaczenia i spróbować rozpoznać ponownie. Jeśli to nie pomaga, można spróbować zmienić typ bloku na tabelę, co program zdaje się odczytywać delikatnie sprawniej. A jeśli i to nie pomaga, to niestety trudno — przepadło i fragment musi iść do tyłu. Jeżeli odpowiednio powiększyliśmy obraz, to straty z tego powodu nie będą dotkliwe. Ważny jest też poprawny wybór języka rozpoznania — przy nieodpowiednim ustawieniu ryzyko, że program źle rozłoży między warstwy umlauty, ogonki i inne dodatki, znacznie wzrasta. Bardzo istotną rzeczą jest także usuwanie zaznaczeń kodów kreskowych, gdyż z obrazu docelowego są one wycinane, co bywa sporym kłopotem i jest bardzo widoczne. Da się to wprawdzie w opcjach wyłączyć i program nie szuka w ogóle kodów przy rozpoznawaniu, aczkolwiek jakoś ta opcja przynajmniej w mojej wersji 11 nie chciała się zapamiętać i resetowała wciąż po zamknięciu programu. Zwykle w książkach bibliotecznych jest jeden lub dwa kody, to względnie niewiele, trzeba kliknąć i skasować taki blok. Czasami zdarza się też, że fragment tekstu zostaje rozpoznany jako kod kreskowy — bezwzględnie trzeba takie bloki likwidować.

Najbardziej problematycznymi fragmentami dokumentów są reklamy i tabelki. FineReader nie umie rozpoznać tekstu, który jest złożony pod kątem, lub jest jakiś mocno nietypowy — co się najczęściej zdarza właśnie w reklamach. Trzeba czasem mocno pokombinować z blokami. Jeżeli kąt nachylenia nie jest bardzo duży, można spróbować zaznaczyć każdą literę osobno, czasem się udaje to rozpoznać i zsegmentować. Tabelki natomiast zwykle rozpoznają się źle. Szczególnie takie, które mają różne kierunki tekstu. Trza to wszystko pozaznaczać i całą strukturę tabeli czasem zbudować od zera. Dużo pracy, jednak się opłaca.

Kolejnym kłopotem są nagłówki wpuszczone i dopiski na marginesach. Każdy z nich musi znaleźć się w osobnym bloku, gdyż program nie umie odczytać w jednym bloku tekstów z różnymi pozycjami linii bazowej. Podobnie jest z inicjałami jeżeli są wpuszczone. Rzeczą beznadziejną są natomiast złożone wzory matematyczne. Kombinować z blokami jak najbardziej można, jednak i tak kończy się to niedobrze. Na razie nie znam skutecznego sposobu. W takich przypadkach duża rozdzielczość wejściowa jest obowiązkowa, inaczej nie będzie się dało tego nawet przeczytać.


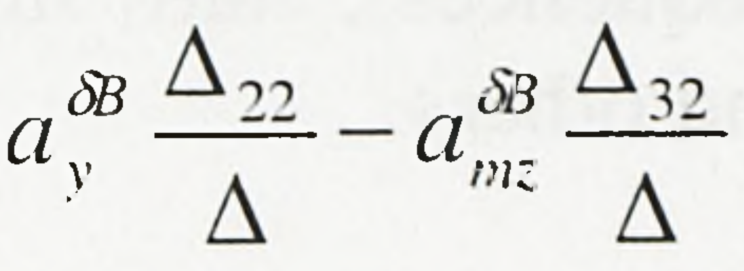
Eksport
Jeśli już wszystko mamy pozaznaczane i poprawione, możemy przystąpić do eksportu. Jak wcześniej wspomniałem coś tam się poustawiać da, mamy więc dwie możliwości: eksportujemy w maksymalnej jakości, co jest do większości rzeczy zalecane i bezpieczne — pliki jednak będą dość duże; alternatywnie używamy niestandardowego ustawienia jakości, co powoduje, że obraz będzie bardziej skompresowany — w przypadku dokumentów o czystym papierze i względnie dobrej jakości druku można śmiało stosować ten sposób i zyskać trochę na rozmiarze. Niestety nic poza tym ustawić się nie da, więc nie ma co liczyć na wielką optymalizację. Trochę jednak można, więc do eksperymentów zachęcam.
- Jako zabytkowe definiuję tu raczej wszystko, co wykracza poza obszar współcześnie produkowanych dokumentów. Włączyć tu można także względnie nowe rzeczy, które z powodu uszkodzeń mają cechy zbieżne z dokumentami zabytkowymi, na przykład niebiałe tło lub skazy na papierze, a także niedokładnie wykonany druk, słaby kontrast itp.
- FineReader 12 ma funkcję PreciseScan, która tutaj jednak większego zastosowania nie ma.
- O tym, dlaczego tak jest, napiszę innym razem. Na razie można wierzyć na słowo, lub nie wierzyć wcale : ).
- I tak znaczniki i inne zaawansowane rzeczy lepiej w takich przypadkach robić po konwersji, o ile w ogóle jest sens.
- Zaznaczyć muszę, że domyślne 45 jest trochę poniżej granicy bezpieczeństwa, trza podnieść do minimum 50. Więcej o tym napiszę przy okazji przetwarzania obrazów prawdziwie czarnych i białych.
- A tego się po FineReaderze spodziewać należy raczej w każdym przypadku
- Co nie zawsze się zdarza i czasem naprawdę dziwne rzeczy się dzieją. Ufać temu nie sposób.
- W starszych wersjach był to poważny problem, zdaje się, że został znacznie poprawiony w wersjach nowszych, niemniej uważać trzeba.
- Bardzo źle natomiast się to kończy dla grafik, które są wypełniane liniowaniem, o ile linie są poziome lub pionowe. Trzeba wtedy użyć trybu czterowarstwowego i pozaznaczać takie ilustracje.